2025年、学ぶプログラミング言語としてRustにしました。このあたりの話は過去記事に書きました。なんとなくの静的型検査が実装できたところで、一旦中断!(ちょっと飽きてきたのもある)
将来、再開した時の自分宛にメモ書きを残しておく、という日記です。
構文解析までは「Go言語でつくるインタプリタ」を参考にしながら順調に進みましたが、意味解析でASTを辿りながらツリー構造を構築するところでRustの洗礼を浴びました。。
過去記事でインプットは以下の1冊、アウトプットはC言語コンパイラと書いていましたが、
他にも色々参考にさせていただきました。参考資料&書籍は以下のとおりです。
- The Rust Programming Language 日本語版 - The Rust Programming Language 日本語版
- Effective Rust - O'Reilly Japan
- Go言語でつくるインタプリタ - O'Reilly Japan
- 型システムのしくみ ― TypeScriptで実装しながら学ぶ型とプログラミング言語 – 技術書出版と販売のラムダノート
- ふつうのコンパイラをつくろう | SBクリエイティブ
- 言語実装パターン - O'Reilly Japan
- プログラミング言語C - 共立出版
処理の流れ
Rustのファイルの置き方、というか mod の使い方に最初は戸惑った。今でもあんまり分かってない気がする。「プログラミングRust」を参考に、最終的に以下の構成に落ち着いた。
src ├── bin │ └── foo.rs ├── lexer │ └── token.rs ├── lexer.rs ├── lib.rs ├── parser │ ├── ast.rs │ ├── parser_for_expressions.rs │ ├── parser_for_external_items.rs │ └── parser_for_statements.rs ├── parser.rs ├── sema │ ├── env.rs │ ├── scope_checker.rs │ ├── semantic_checker.rs │ └── type_checker.rs └── sema.rs
// lib.rs mod lexer; mod parser; mod sema; pub fn compile(input: &str) { let mut parser = create_parser(input); let ast = parser.parse_program(); sema::semantic_analyze(ast) // TODO: }
コンパイラのフェーズごとにモジュールを作り、データを流していく。
- lexer
- 入力となるC言語ソースコード文字列 → トークン列
- parser (構文解析)
- トークン列 → AST
- sema (意味解析)
- scope_checker
- AST → スコープツリー
- semantic_checker
- AST → 文や式の妥当性チェック(トップレベルに
breakがないか、returnがグローバルにないか、などなど)
- AST → 文や式の妥当性チェック(トップレベルに
- type_checker
- AST + スコープツリー → 静的型検査
- scope_checker
構文解析
lexer, parserあたりの実装は、「Go言語でつくるインタプリタ」を参考にした。parserの処理はGoと比べてRustだから有利/不利、というのは特に感じなかった。
Rustのenum
ASTの表現はRustの方がしやすいと感じた。enumで代数的データ型を表現できるのがとても強力だった。パターンマッチで網羅性をコンパイル時に担保できる、かつ、Destructureで内部の値を各変数に分配できる。ソースコードがとても簡潔に書けるし読みやすい。
Rust最高!という気分。
Rustで再帰的なデータ構造
「Go言語でつくるインタプリタ」ではASTをExpressionを再帰的に参照するツリー構造で表現している。
type Node interface { TokenLiteral() string } type Expression interface { Node } ... type InfixExpression struct { Token token.Token Left Expression Operator string Right Expression } func (oe *InfixExpression) TokenLiteral() string { return oe.Token.Literal } ...
Rustではデータはスタックに置かれる。そのため、コンパイル時にメモリサイズが分かる必要がある。再帰的なデータ構造だと、どこまで再帰が続くか分からないためサイズが決まらないためコンパイルエラーになる。
pub enum Expression { ... Infix { operator: String, left: Expression, right: Expression, }, ... }
left , right をポインタにして、実体はスタックではなくヒープに置くようにすればいい。Rustでは Box<T> を使ってこれを実現できる。実体のサイズは不確定だが、ポインタのサイズは決まっているためスタックに置ける。
pub enum Expression { ... Infix { operator: String, left: Box<Expression>, // Expressionそのものではなく、ヒープを指すポインタ right: Box<Expression>, }, ... }
スタックに確保された Box<T> が解放されるタイミングで、ヒープに置かれた実体のメモリも解放される。
意味解析で壁にぶつかる
構文解析までは「Go言語でつくるインタプリタ」と大きな違いはなかったけど、この先が大きく違う。
「Go言語でつくるインタプリタ」ではASTを辿りながら式の評価を行う。ore-c-rustでは、ASTを辿りながら意味解析をする。意味解析では大きく2つのステップに分けてる。
- ASTを辿ってスコープツリーを構築し、変数名と型定義のマッピングをする
- ASTを辿って型解析をする
これをRustで実装するのが簡単ではなく、Rustコンパイラにたくさん怒られた。所有権と借用チェッカと仲良くならないといけない。
スコープツリーの構築
スコープとASTノード
「Go言語でつくるインタプリタ」では、ソースコード上に登場する変数や関数を格納しておくために Environment というstructを実装してる。 store map[string]Object で変数や関数を管理している。 outer で親スコープを持つ。
type Environment struct { store map[string]Object outer *Environment } func (e *Environment) Set(name string, val Object) Object { e.store[name] = val return val } func (e *Environment) Get(name string) (Object, bool) { obj, ok := e.store[name] if !ok && e.outer != nil { obj, ok = e.outer.Get(name) } }
ASTの各ノードを辿りながら、新たな変数が登場したら Environment に追加していく。変数を取得する際は、まず自分自身から取得し、存在しなければ親スコープから取得することを試みる。
さらに、ASTを評価した際に Function というstructのオブジェクトを作り、このstructに関数スコープの Environment を持たせることで、関数本体を表すASTノードとスコープの関連づけをしている。直感的・シンプルで分かりやすい。
type Function struct { Parameters []*ast.Identifier Body *ast.BlockStatement Env *Environment }
ここまででオブジェクトの関連は以下のようになる。
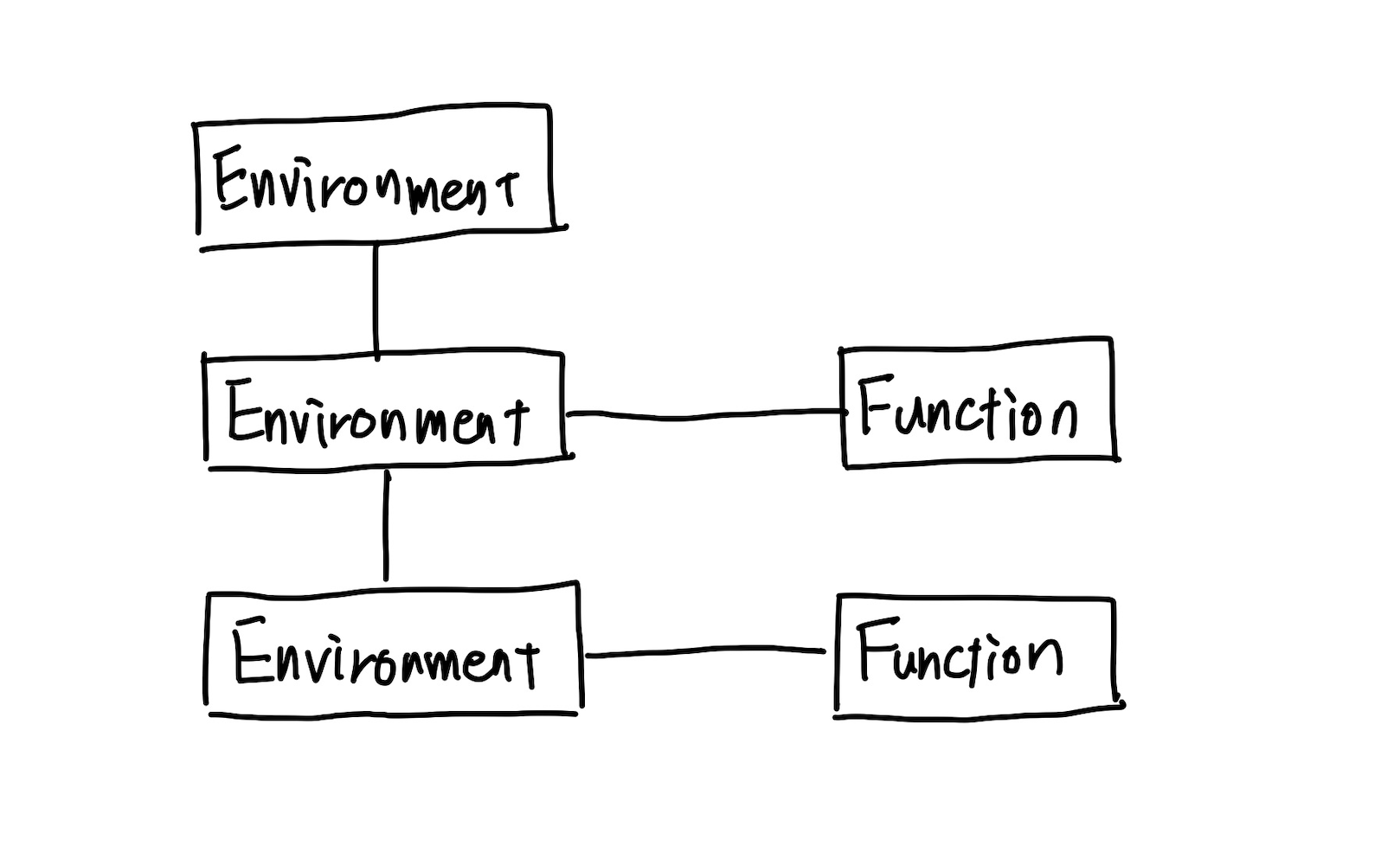
ある Environment が、 Function と子の Environment と2つのオブジェクトから参照されている。 Function 経由で参照される場合は変数が追加される時である可能性があるため書き込まれる。子の Environment から参照される場合は変数を探す時であるため書き込みはなく読み取りのみとなる。
これをRustでは簡単に表現できない!
借用チェッカ
Rustでは参照は借用と呼ばれ、いつか借り元へ返さないといけない。借用チェッカによっていくつかルールを守っているかどうかコンパイル時にチェックされる。
ルールの1つ:
- アイテムの所有者に加えて以下のどちらかだけが存在できる
- そのアイテムへの任意の数の不変参照
- そのアイテムへの1つの可変参照
- ただし、両方を持つことはできない
このルールによって所有者の操作も制限される。参照が存在する場合は、所有者であってもアイテムの更新はできない。所有者による更新とは言っても、一時的に可変参照を使って更新すると考えると納得できる(可変参照は1つしか取得できないため)。
上記のことから、先ほどの Environment の表現は子の Environment からの参照が存在する状態で、”関数”からも参照させて Environment に新たな変数を追加したいわけだが、追加するということは可変参照が必要なのだけど、一方で子から親への不変参照も必要。これはRustでは上記のルールによってコンパイルエラーになる。”関数”を Environment の所有者にしたとしても、これもコンパイルエラーで実現できない。
struct Environment<'a> { parent: &'a Environment // 不変参照 } struct Function { environment: Environment // 所有 }
Goのように気軽にポインタを繋ぐ設計は破綻。だけど、Rustでもスマートポインタ( Rc や RefCell )を使うと近いことを実現できる。今回はRust学習のため、使わないことにした。
- RefCell
と内部可変性パターン - The Rust Programming Language 日本語版 - 循環参照は、メモリをリークすることもある - The Rust Programming Language 日本語版
解決策:ID管理による疑似ポインタ
scope_checker.rsに実装。今回の実装では、 Environment 相当のstructを Scope と命名した。
では、スマートポインタを使わずにASTノードとスコープの関連づけをどうするか?
それは全ての Scope の所有権を持つ管理者( Env )を作り、各 Scope はID(数値)で管理するというアプローチにした。(Arenaパターンと呼ばれるパターンに近いような、そうでもないような)
Scope にIDを用意して、各 Scope では親 Scope のIDを持たせる。そして、 Env というstructを用意して全ての Scope の所有者にする。ASTを辿るときは Env の可変参照を持ち回る。
pub struct Scope { pub id: usize, // 親Scopeのid parent: Option<usize>, /// シンボル名と型名を対応表 entities: HashMap<String, TypeRef>, } struct Env { scope_table: HashMap<usize, Scope>, } impl Env { fn find(&self, scope: &Scope, name: &str) -> Option<TypeRef> { // 引数の `scope` から、 `name` で指定された変数を探す let mut result = scope.find(name); ... let parent_id = scope.parent; // 見つからなければ `scope` から親ScopeのIDを取得する ... result = self.scope_table.get(parent_id).and_then(|p| p.find(name)); // `scope_table` から親Scopeを取得して、変数を探す // 繰り返し... } }
さらに、ASTノードと Scope の関連づけも Env に持たせる。
struct Env { scope_table: HashMap<usize, Scope>, node_scope: HashMap<Node, usize>, }
これでASTを辿りながら Scope を構築できる。同じ要領で、型名と型定義の解決もする。
※ 現状、型のテーブルを Env で管理してしまっているけど Scope で管理するように直すのが正しいはず。そうしないと、Cソースコードで関数内でtypedefを定義するとグルーバルスコープで同名のものが定義されていた場合にコンフリクトしてしまう。。
GoをベースにRustでの実装し直すというは、単なるロジックの移植ではなくメモリ管理とデータの所有権の再設計だった。GCなしでメモリを安全に扱うためにRustコンパイラが助けてくれるというのが少し分かった気がする。
型検査
型検査は「型システムのしくみ」という本で学んだことを実装した → 前回のブログ記事。
担当しているのはtype_checker.rs。ASTを辿りながら各式が返す型を評価する。ここで上述のscope_checker.rsで構築したスコープツリーを利用する。ASTノードから Scope を取得 → Scope から変数定義を取得 → 変数定義から型定義を取得 → 取得した型定義を使って型検査する、という処理の流れ。
例えば int a = f(x); というCソースコードの文があったら、左辺の型定義と右辺の型定義を手に入れて、同じ型かどうかチェックする。
本を読むまではとてもハードルが高く感じていたのだけど、「型システムのしくみ」がとても良い本で勉強になったのでありがたい。
おしまい
再開した時の自分宛にメモはここまで!再開して次にやりたいことは、アセンブリを生成したい。
けど、その前にやった方が良さそうなことがあるなぁ。。
- 型テーブルを
EnvじゃなくてScopeに持たせる - 再起的な関数定義いける?
- プリプロセッサの対応(特にinclude)
- printfとか(暫定的に組み込み関数にする?)
- 中間表現(IR)はスキップで良いかな..
