WebブラウザでCASL2を試せるCASL2 Playgroundをつくってみた
この記事は個人開発 Advent Calendar 2021の7日目の記事です!
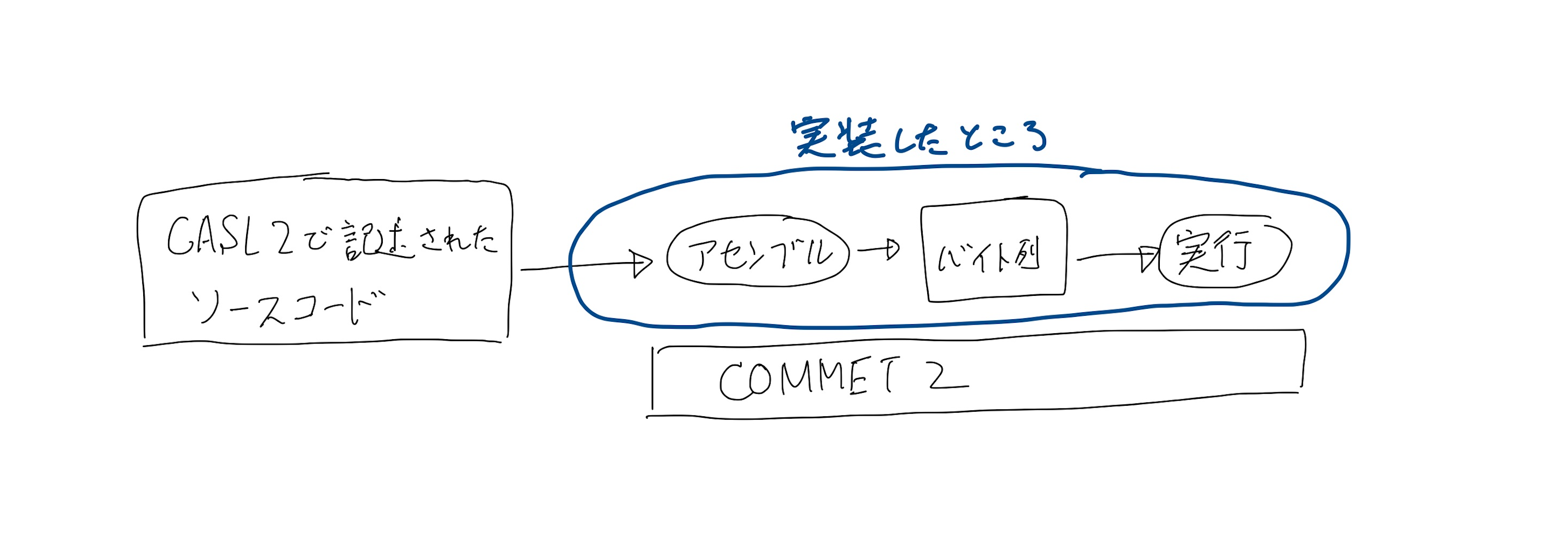
CASL2とは基本情報技術者試験のために策定されたアセンブラ言語です!そのCASL2をWebブラウザ上で書いて実行できるWebサービスをつくりましたという日記です。
なぜつくったのか?
自分が欲しいとかこういう人に使って欲しいという理由ではなく、自分の勉強のためにつくりました。勉強のための車輪の再発明。
今年の2月の記事ですが、「計算機プログラムの構造と解釈」という本を読み始めました。
読み終えたんですけど最後の章「5 レジスタマシンによる計算」がうーむ。。という感じだったので似たようなものつくってみようと思ったのがきっかけです。
アセンブラ言語に全然馴染みがなくパッと思いついたのがCASL2だったので、Webブラウザ上で試せるようなツールをつくってみるか!とTypeScriptで実装しました。UIはJavaScriptでDOMをいじいじ...
「計算機プログラムの構造と解釈」のSchemaで実装されたアセンブラを元に、TypeScriptで実装していく形で実装を始めました。途中で家で積ん読になってた「言語実装パターン」という書籍を見つけこちらも途中から参考にします。最初から読んでいれば...という気持ちになるところもあり、すでに作り直したい部分がちらほら。
「計算機プログラムの構造と解釈」は、先日のブログ記事でも紹介させていただきましたが、hiroshi-manabeさんによる翻訳を読みました。
「言語実装パターン」は、O'Reillyの本です。

開発メモ
アセンブラってなんですか?
「計算機プログラムの構造と解釈」でのレジスタマシンとアセンブラの記述を自分なりのざっくり理解を書くと
- レジスタと呼ばれる記憶素子の中身を操作する命令を順に実行するコンピュータがレジスタマシン
- レジスタマシンを設計するためには、レジスタと演算を表すデータパス、それらの演算を正しく並べるコントローラが必要で、図で書いて表現できる
- だけど複雑になってくるとすぐに図で記述できなくなる
- そこで、レジスタマシン用言語で作って記述しよう。この言語(テキスト形式)を機械語(バイナリ形式)に変換するプログラムがアセンブラ
今回つくろうとしてるものに当てはめると、CASL2という言語をCOMMET2(基本情報技術者試験のために設計された仮想のコンピュータ=レジスタマシン)の機械語に変換し実行する、ということになる。
「言語実装パターン」ではアセンブラは、「パターン26 バイトコードアセンブラ」の章で
と同様のことが記述されてる。
さらに「言語実装パターン」では、アセンブラは4つの重要要素があるとも記述されている。
- 大域データ空間の大きさ
- コードメモリ
- mainプログラムのアドレス
- 定数プール
大域データ空間はメインメモリのことで、COMMET2のメインメモリは、1語16ビットで65536語の容量です。コードメモリというのは、メインメモリにアセンブラによって生成されたバイナリ形式の機械語そのものが格納される、ということ。mainプログラムのアドレスは、メインメモリのどのアドレスがプログラムの開始位置なのかを示す。定数プールは、文字列や浮動小数点、関数名などのオペランドをコードメモリ内に収まらないので別のアドレスに保管することを示していて、CASL2で言うとソースコードに記述されるラベルが該当します。
つまり、テキスト形式のソースコードから変換したバイナリ形式形式の機械語も定数も同じメインメモリ上に置かれる。
と、ここで気がつく。「計算機プログラムの構造と解釈」を読んでいてあまり腹落ちしなかったのは、この機械語とメインメモリとが具体的に出てこなかったからなのでは。メモリもリストとGCのところで抽象化してたからかもしれないなぁ。「計算機プログラムの構造と解釈」の 5 レジスタマシンによる計算 の書き出しを読み直すと以下のように書いてある。
典型的なレジスタマシンの命令は、レジスタの中身に基本的な演算を適用し、その結果をほかのレジスタに割り当てるというものです。レジスタマシンにより実行されるプロセスをこのように記述すると、従来式コンピュータの"機械語"に非常によく似ているように見えます。しかし、ここではある特定のコンピュータの機械語を扱うのではなく、いくつかのLisp手続きについて調べ、それぞれの手続を実行するための個別のレジスタマシンを設計していくことにします。そのため、課題に対する私たちのアプローチは、機械語のプログラマというよりも、ハードウェア設計者としての視点によるものとなります。
「ある特定のコンピュータの機械語を扱うのではなく」のせいでかえって取っ付きづらくなっている気がする。ハードウェア設計者としての視点...ワカラン...
ラベルの取り扱い
CASL2のソースコードを見ていて、普段のプログラミング言語と明らかに違うなぁと思うのはラベル。ソースコードのとある行にラベルづけをしておく。if文で条件分岐するようなことをしたい場合は、条件を満たす場合はラベルAにジャンプ、条件を満たさない場合はラベルBにジャンプというように使う。他にも関数呼び出しのようなことをしたい場合もラベルを使うし、定数名のようにラベルを使うこともできる。
「計算機プログラムの構造と解釈」では以下のように記述されている。
アセンブラは、命令実行手続きを生成する前に、ラベルの参照先をすべて知っておく必要があります。
これは分かるな。例えば以下のようなコードがあったとする。 ADDA でレジスタ GR1 とラベル TWO のアドレスにセットされている数値を加算する、というコード。ラベル TWO に数値 2 がセットされる。
SAMPLE01 START
LAD GR1,1
ADDA GR1,TWO
TWO DC 2
END
このソースコードを上から順に解析すると、3行目時点ではラベル TWO がまだ登場していないため、存在するラベルなのか?どの位置を指しているのか?ということが分からない。だから 命令実行手続きを生成する前に、ラベルの参照先をすべて知っておく 必要が出てくる。
まだ登場していないラベル(や関数名や変数や色々)を参照することを前方参照と言うらしい。
ラベルの前方参照とbackpatching
実装としては入力となるソースコードを行ごとでループして走査、 labelMap = Map<Label, Array<行>> というMapにラベル毎に集約しておく。集約する過程で各行の命令とオペランドからバイト数が分かるのでラベルのメモリアドレスも分かる。集約後、Mapの全エントリをループすることで各行をもう一度走査することで全てのラベルにセットされた値も把握しながら解析できる。
ただこれ、ソースコード全体を2回ループしてるし、同じようなやってるような感じもするけどどうなのか。
「言語実装パターン」の パターン26 バイトコードアセンブラ を読んでみる。アセンブラの変換のパターンとしては「パターン29 構文手動変換器」であると書かれている。ここで言う構文手動変換器とは、入力1行を読んだら変換先の1行を生成する、というもので前方参照を扱えないパターンと書かれている。
ラベルの前方参照ができないと困るじゃないか。
解決策として backpatching という方法が紹介されている。
Labelを表すオブジェクトに isForwardRef フラグというのを用意する。
type Label = { label: string memAddress: number isForwardRef: boolean }
さらに、「後から前方参照を解決すべき被演算数のリスト」を forwardRefs = Map<string, Array<行>> で管理する。
const forwardRefs = Map<string, Array<行>>
先程のCASL2コード例をもう一度。
SAMPLE01 START
LAD GR1,1
ADDA GR1,TWO
TWO DC 2
END
この例だと、アセンブラは入力となるCASL2ソースコード3行目で TWO というラベルを見つけたときに、以下のようにラベルMapとforwardRefsに追加する。
if (!labels.has("TWO")) { // 前方参照されているラベル(isForwardRef = true)としてラベルMapに追加 labels.set("TWO", { label: "TWO", memAddress: 0, isForwardRef: true }) } operandPos = ... bytecodeList[operandPos] = ... // bytecodeListは最終的に出力する機械語であるバイト列 if (labels.get("TWO").isForwardRef) { // "TWO" を前方参照してるオペランドの位置を追加 if (forwardRefs.has("TWO")) { forwardRefs.get("TWO").push(operandPos) } else { forwardRefs.set("TWO", [operandPos]) } }
4行目で TWO ラベルが定義されると、「後から前方参照を解決すべき被演算数のリスト」を走査して修正する。
// ラベル "TWO" のアドレス currentMemAddress = ... if (!labels.has("TWO")) { labels.get("TWO").memAddress = currentMemAddress labels.get("TWO").isForwardRef = false } ... forwardRefs.get("TWO").forEach(operandPos => { bytecodeList[operandPos] = currentMemAddress })
こういうイメージか。たしかにソースコードの行すべてをもう一度走査することに比べたら「後から前方参照を解決すべき被演算数のリスト」を走査した方が効率良さそう。
構文手動変換器パターンのように、ソースコード全体を1回だけ走査することを1パスと呼ぶみたい。1パスは単純だけど、そのままだと前方参照ができない、入力と大きく並び順が異なる出力を生成できない、といったデメリットがある。1パスに対して、そうでないものをマルチパスと呼ぶらしい。
おわりに
学びたいポイントが次から次へと出てきて困るけど楽しいという感じでした!
自分の実装は、アセンブラとして機械語を生成する処理と、Commet2上で動きをシミュレートするための関数と、両方をごちゃっと実装してしまっている感じがあって分かりづらい。Commet2で動かす部分については「言語実装パターン」に書かれている パターン28 レジスタ方式バイトコードインタプリタ を参考しながら機械語を入力とするインタプリタとして作り直すと良さそう。
他にもbackpatchingで書き直したり、全然別の構文手動変換器ではない変換器をつくってみたりもしたいなぁ。